Hash Table
April 24, 2020
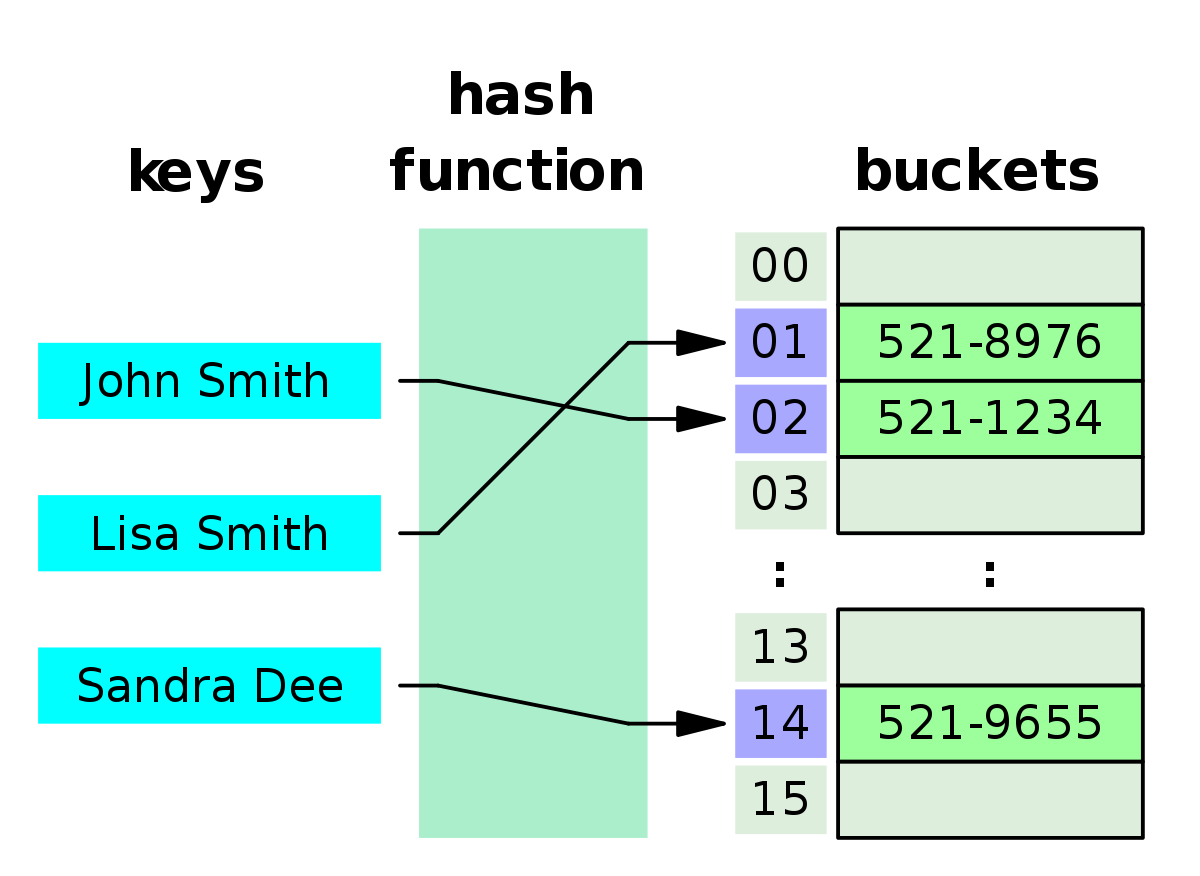
What is hash table?
Well, let’s say a hash table is looks like an array with a difference. In an array you know the index and you can access to the item by an index. In hash table you don’t have the index. Instead you have the key which could be an string, int, object or any other type. We are using hash tables when there is a relation between key and value. A dictionary is a sample of hash table.
A hash table is a typical way of implementing an associative array. When a hash table’s created internally, it’s really an array-based data structure where we add extra functionality to get us past the limitations of an array. We use the term bucket to describe each entry or place for a key-value pair to go in a hash table. We’ll never add just a key or just a value. We’ll always add a pair.
When we add a new pair to the hash table, the key will go through a hash function and then an integer value will pop out. Depending on the function, it could be a rather large number, so we can’t just use it as an array index in our implementation but we can use it to calculate an array index. This requires some logic and it’s all done within the hash table implementation.
There’s a little bit of processing involved for retrieval and insertion, but it’s the same amount of processing every time, no matter how big the hash table is. This means that lookup, insertion and deletion all take O(1) or constant time. The only reason this might differ is if you have collisions and must handle them with separate chaining, which create linked lists with additional values. (In case two keys have same hash we will use linked list in exact position of array for keep two key-values (or more))